

Meta just released the newest version of its open generative AI model called Llama 3, Actually, they released two different sizes of Llama 3 for now, with more on the way!
Meta describes the new models — It's a significant improvement over the previous version, Llama 2. Llama 3 comes in two sizes: 8 billion parameters and 70 billion parameters. In general, models with more parameters tend to perform better. Meta claims that Llama 3 models outperform other similar-sized models on various tasks, making them some of the best generative AI models available today. To achieve this performance, Meta trained Llama 3 on massive datasets using special computer systems with thousands of graphics processing units. In fact, Meta says that, for their respective parameter counts, Llama 3 8B and Llama 3 70B — trained on two custom-built 24,000 GPU clusters — are are among the best-performing generative AI models available today.
That’s quite a claim to make. So how is Meta supporting it? Well, the company points to the Llama 3 models’ scores on popular AI benchmarks like MMLU (which attempts to measure knowledge), ARC (which attempts to measure skill acquisition) and DROP (which tests a model’s reasoning over chunks of text). As we’ve written about before, the usefulness — and validity — of these benchmarks is up for debate. But for better or worse, they remain one of the few standardized ways by which AI players like Meta evaluate their models.
Llama 3 8B outperforms other leading open models like Mistral’s Mistral 7B and Google’s Gemma 7B, each containing 7 billion parameters, across at least nine benchmarks. These benchmarks include MMLU, ARC, DROP, GPQA (comprising biology, physics, and chemistry questions), HumanEval (for code generation), GSM-8K (math word problems), MATH (another mathematics benchmark), AGIEval (for problem-solving), and BIG-Bench Hard (a commonsense reasoning evaluation).
While Mistral 7B and Gemma 7B were released last September and may not be considered cutting-edge, Meta claims that in some benchmarks, Llama 3 8B performs only marginally better. However, Meta also asserts that its larger-parameter-count model, Llama 3 70B, competes effectively with flagship generative AI models like Google's Gemini 1.5 Pro.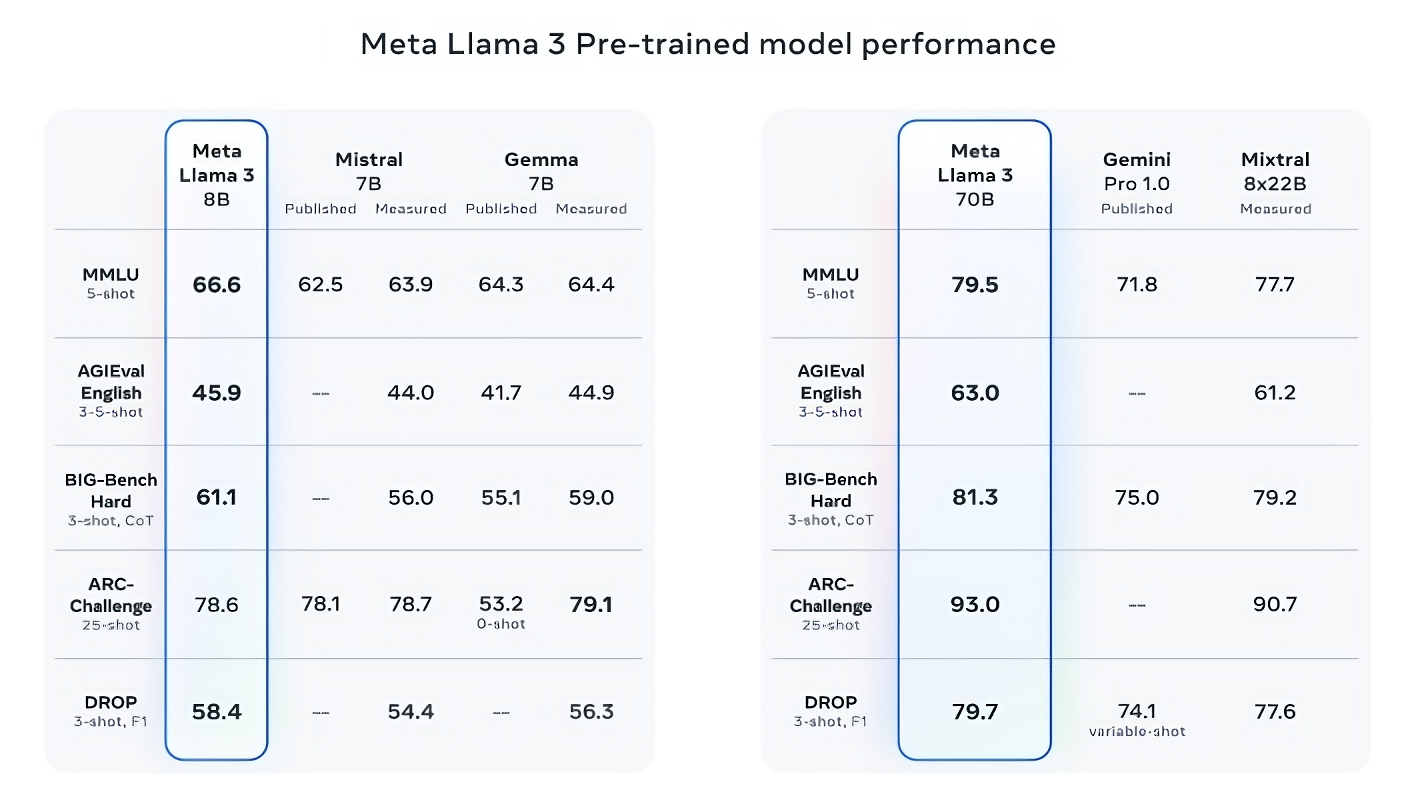
Image Credits: Meta
Llama 3 70B outperforms Gemini 1.5 Pro across multiple benchmarks, including MMLU, HumanEval, and GSM-8K. Although it doesn't match the performance of Anthropic's top model, Claude 3 Opus, Llama 3 70B still achieves higher scores compared to the second-weakest model in the Claude 3 series, Claude 3 Sonnet, across five benchmarks: MMLU, GPQA, HumanEval, GSM-8K, and MATH.
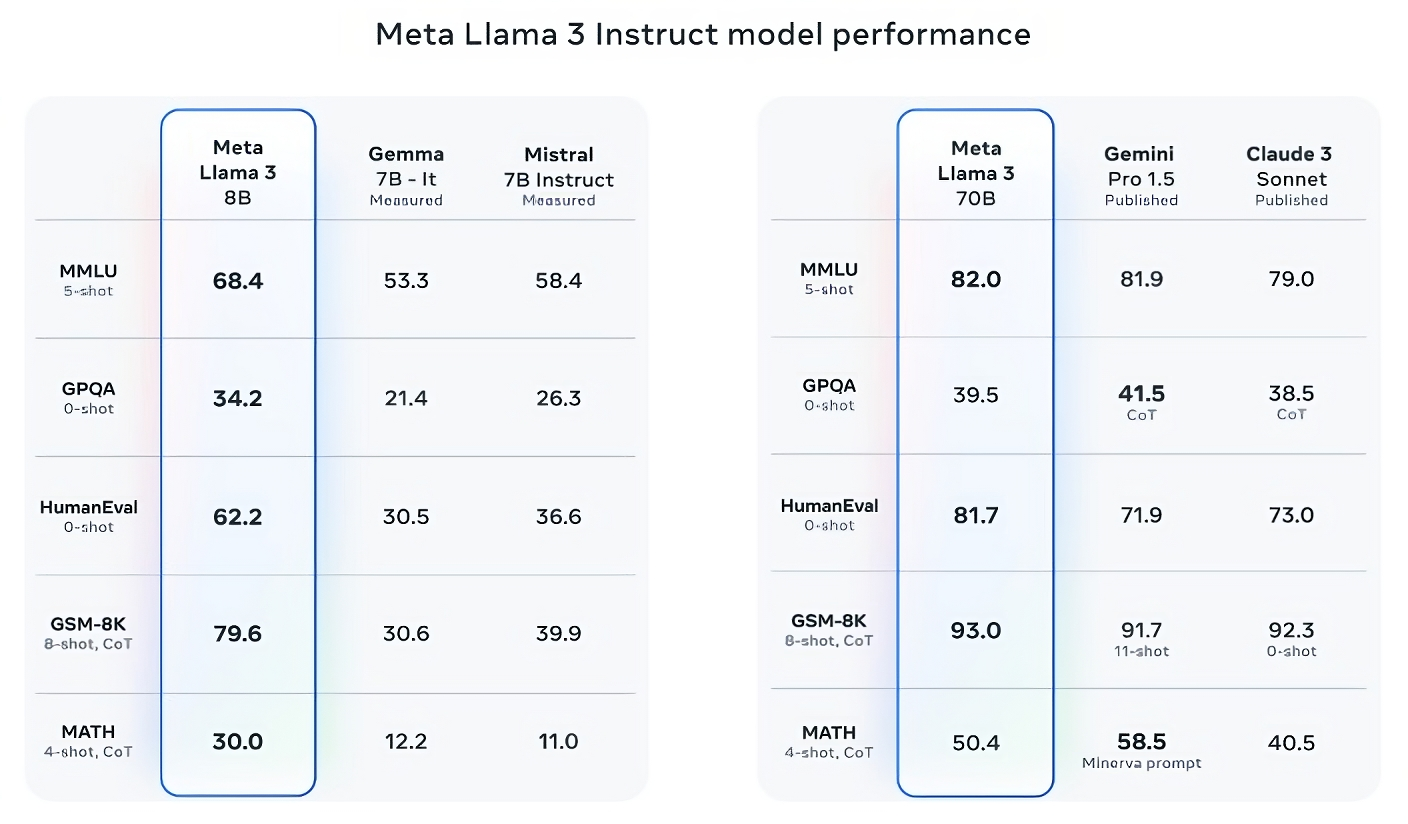
Image Credits: Meta
For what it’s worth, Meta also developed its own test set covering use cases ranging from coding and creative writing to reasoning to summarization, and — surprise! — Llama 3 70B came out on top against Mistral’s Mistral Medium model, OpenAI’s GPT-3.5 and Claude Sonnet. Meta says that it gated its modeling teams from accessing the set to maintain objectivity, but obviously — given that Meta itself devised the test — the results have to be taken with a grain of salt.
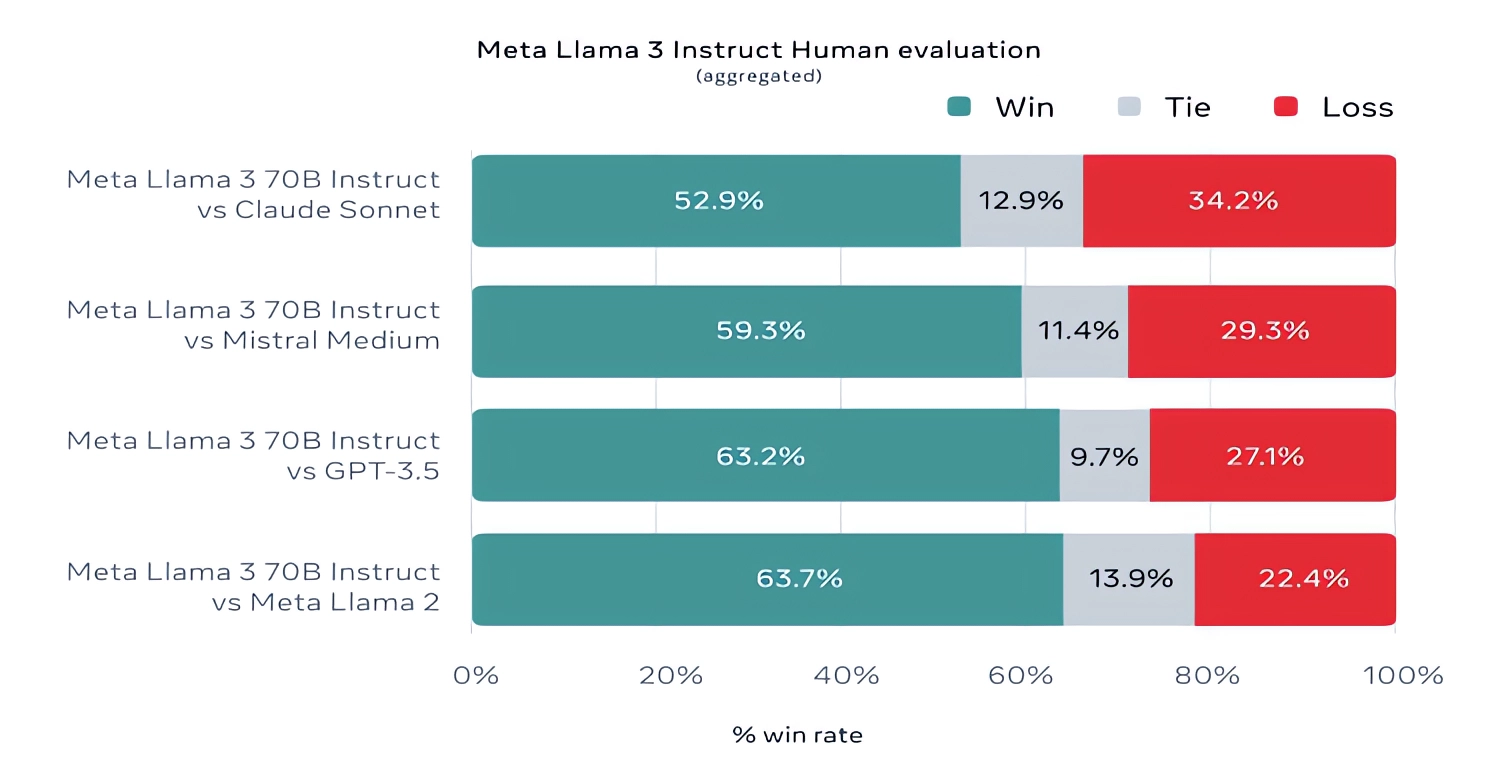
Image Credits: Meta
In simpler terms, Meta suggests that users of the new Llama models can anticipate enhanced "steerability," reduced likelihood of refusing to answer questions, and improved accuracy across various domains, including trivia, history, STEM fields like engineering and science, and general coding recommendations. This improvement is attributed in part to the utilization of a significantly larger dataset, comprising a staggering 15 trillion tokens or approximately 750 billion words — seven times the size of the Llama 2 training set. (In AI terminology, "tokens" refer to segmented units of raw data, akin to the individual syllables within a word like "fantastic."
Meta has not disclosed the exact source of this data, stating only that it was sourced from "publicly available sources." However, they mentioned that it encompasses four times the amount of code compared to the Llama 2 training dataset. Additionally, approximately 5% of the dataset contains non-English data in around 30 languages, aimed at enhancing performance across languages beyond English. Furthermore, Meta acknowledged using synthetic data, which refers to AI-generated data, to produce lengthier documents for training the Llama 3 models. This approach has sparked some controversy due to its potential performance implications.
"Meta explains that although the models currently released are fine-tuned specifically for English outputs, the expanded data diversity enhances their ability to discern subtleties and patterns. As a result, they demonstrate robust performance across a range of tasks."
Numerous providers of generative AI regard their training data as a strategic asset and therefore maintain strict confidentiality around it. However, divulging specifics about training data can also expose companies to intellectual property-related legal challenges, further discouraging transparency. Recent investigations uncovered that Meta, in its efforts to stay competitive in the AI landscape, once utilized copyrighted e-books for training its AI models despite warnings from its legal team. Consequently, Meta and OpenAI are currently embroiled in a lawsuit filed by authors, including comedian Sarah Silverman, over the alleged unauthorized utilization of copyrighted data for training purposes.So what about toxicity and bias, two other common problems with generative AI models (including Llama 2)? Does Llama 3 improve in those areas? Yes, claims Meta.
Meta says that it developed new data-filtering pipelines to boost the quality of its model training data, and that it has updated its pair of generative AI safety suites, Llama Guard and CybersecEval, to attempt to prevent the misuse of and unwanted text generations from Llama 3 models and others. The company’s also releasing a new tool, Code Shield, designed to detect code from generative AI models that might introduce security vulnerabilities.
Filtering methods, such as those employed by Llama Guard, CyberSecEval, and Code Shield, have their limitations. For instance, Llama 2 has been known to fabricate responses to inquiries and inadvertently disclose sensitive health and financial data. The efficacy of the Llama 3 models in real-world scenarios, including assessments conducted by academics using different benchmarks, remains to be seen.
Meta announces that the Llama 3 models, currently downloadable and fueling Meta's Meta AI assistant on various platforms like Facebook, Instagram, WhatsApp, Messenger, and the web, will soon be offered in managed form across multiple cloud platforms. These platforms include AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM's WatsonX, Microsoft Azure, Nvidia's NIM, and Snowflake. Additionally, optimized versions of the models for hardware from AMD, AWS, Dell, Intel, Nvidia, and Qualcomm will be released in the future.
While the Llama 3 models may appear to be widely accessible, it's important to note that our description of them as "open" differs from the conventional understanding of "open source." Despite Meta's assertions, the Llama family of models is not entirely unrestricted. While they are accessible for both research and commercial purposes, Meta imposes limitations. Developers are prohibited from utilizing Llama models to train additional generative models. Moreover, app developers with over 700 million monthly users are required to request a special license from Meta, which may be granted or denied at the company's discretion.
Exciting advancements await in the realm of Llama models.
Meta reports that it is presently in the process of training Llama 3 models with over 400 billion parameters. These enhanced models boast the capability to converse in multiple languages, process larger volumes of data, and comprehend images and other forms of data alongside text. This development aligns the Llama 3 series with prominent releases such as Hugging Face's Idefics2.
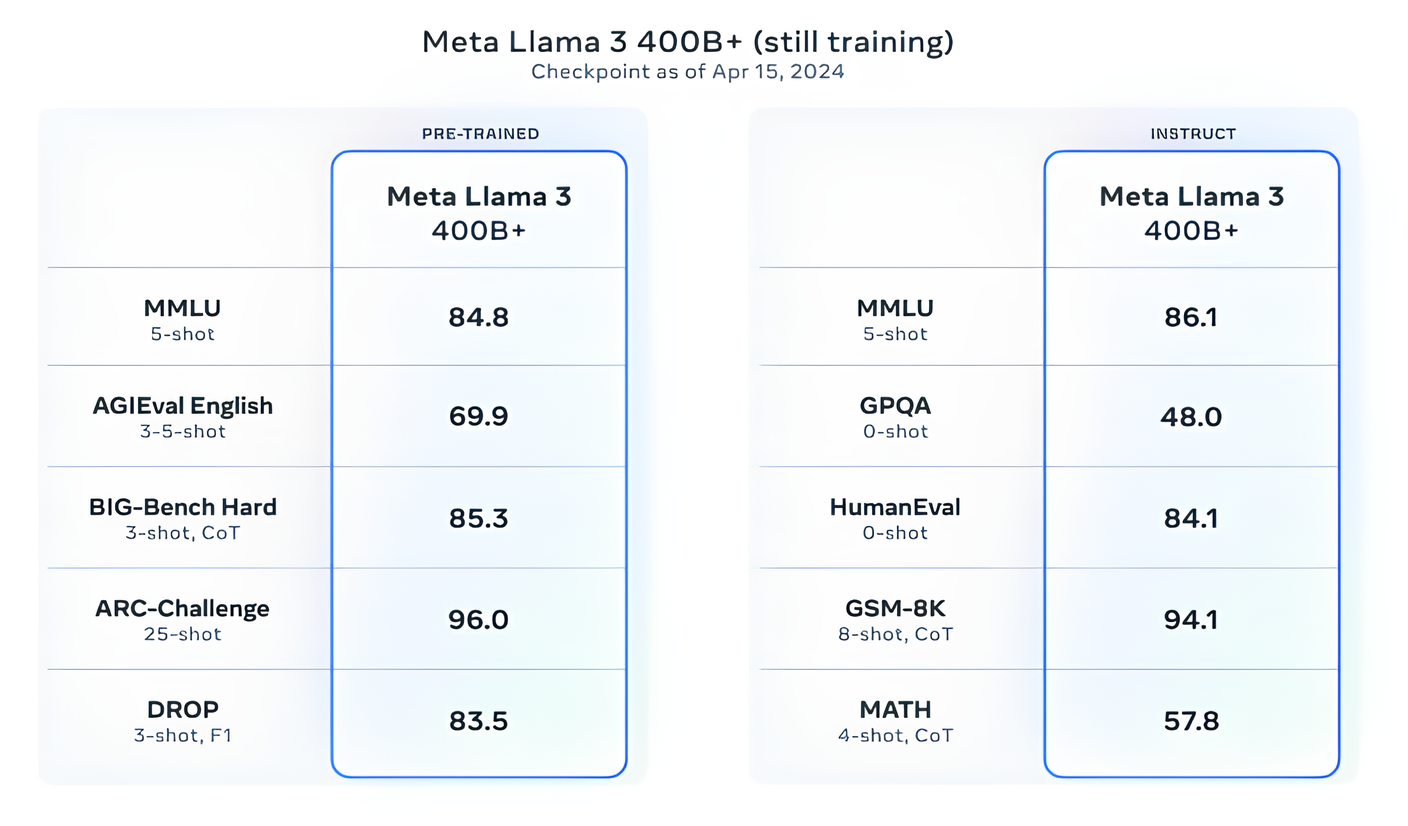
Image Credits: Meta
"Meta expresses its aim to enhance Llama 3 by making it multilingual and multimodal in the near future, with extended contextual understanding and improved performance in core capabilities like reasoning and coding. The company emphasizes that there are exciting developments on the horizon."


0 Comments